Rather than using class() and length(),
vctrs has notions of prototype (vec_ptype_show()) and size
(vec_size()). This vignette discusses the motivation for
why these alternatives are necessary and connects their definitions to
type coercion and the recycling rules.
Size and prototype are motivated by thinking about the optimal
behaviour for c() and rbind(), particularly
inspired by data frames with columns that are matrices or data
frames.
Prototype
The idea of a prototype is to capture the metadata associated with a
vector without capturing any data. Unfortunately, the
class() of an object is inadequate for this purpose:
The
class()doesn’t include attributes. Attributes are important because, for example, they store the levels of a factor and the timezone of aPOSIXct. You cannot combine two factors or twoPOSIXcts without thinking about the attributes.The
class()of a matrix is “matrix” and doesn’t include the type of the underlying vector or the dimensionality.
Instead, vctrs takes advantage of R’s vectorised nature and uses a
prototype, a 0-observation slice of the vector (this is
basically x[0] but with some subtleties we’ll come back to
later). This is a miniature version of the vector that contains all of
the attributes but none of the data.
Conveniently, you can create many prototypes using existing base
functions (e.g, double() and
factor(levels = c("a", "b"))). vctrs provides a few helpers
(e.g. new_date(), new_datetime(), and
new_duration()) where the equivalents in base R are
missing.
Base prototypes
vec_ptype() creates a prototype from an existing object.
However, many base vectors have uninformative printing methods for
0-length subsets, so vctrs also provides vec_ptype_show(),
which prints the prototype in a friendly way (and returns nothing).
Using vec_ptype_show() allows us to see the prototypes
base R classes:
-
Atomic vectors have no attributes and just display the underlying
typeof():vec_ptype_show(FALSE) #> Prototype: logical vec_ptype_show(1L) #> Prototype: integer vec_ptype_show(2.5) #> Prototype: double vec_ptype_show("three") #> Prototype: character vec_ptype_show(list(1, 2, 3)) #> Prototype: list -
The prototype of matrices and arrays include the base type and the dimensions after the first:
vec_ptype_show(array(logical(), c(2, 3))) #> Prototype: logical[,3] vec_ptype_show(array(integer(), c(2, 3, 4))) #> Prototype: integer[,3,4] vec_ptype_show(array(character(), c(2, 3, 4, 5))) #> Prototype: character[,3,4,5] -
The prototype of a factor includes its levels. Levels are a character vector, which can be arbitrarily long, so the prototype just shows a hash. If the hash of two factors is equal, it’s highly likely that their levels are also equal.
vec_ptype_show(factor("a")) #> Prototype: factor<4d52a> vec_ptype_show(ordered("b")) #> Prototype: ordered<9b7e3>While
vec_ptype_show()prints only the hash, the prototype object itself does contain all levels: -
Base R has three key date time classes: dates, date-times (
POSIXct), and durations (difftime). Date-times have a timezone, and durations have a unit.vec_ptype_show(Sys.Date()) #> Prototype: date vec_ptype_show(Sys.time()) #> Prototype: datetime<local> vec_ptype_show(as.difftime(10, units = "mins")) #> Prototype: duration<mins> -
Data frames have the most complex prototype: the prototype of a data frame is the name and prototype of each column:
vec_ptype_show(data.frame(a = FALSE, b = 1L, c = 2.5, d = "x")) #> Prototype: data.frame< #> a: logical #> b: integer #> c: double #> d: character #> >Data frames can have columns that are themselves data frames, making this a “recursive” type:
df <- data.frame(x = FALSE) df$y <- data.frame(a = 1L, b = 2.5) vec_ptype_show(df) #> Prototype: data.frame< #> x: logical #> y: #> data.frame< #> a: integer #> b: double #> > #> >
Coercing to common type
It’s often important to combine vectors with multiple types. vctrs
provides a consistent set of rules for coercion, via
vec_ptype_common(). vec_ptype_common()
possesses the following invariants:
class(vec_ptype_common(x, y))equalsclass(vec_ptype_common(y, x)).class(vec_ptype_common(x, vec_ptype_common(y, z))equalsclass(vec_ptype_common(vec_ptype_common(x, y), z)).vec_ptype_common(x, NULL) == vec_ptype(x).
i.e., vec_ptype_common() is both commutative and
associative (with respect to class) and has an identity element,
NULL; i.e., it’s a commutative monoid.
This means the underlying implementation is quite simple: we can find
the common type of any number of objects by progressively finding the
common type of pairs of objects.
Like with vec_ptype(), the easiest way to explore
vec_ptype_common() is with vec_ptype_show():
when given multiple inputs, it will print their common prototype. (In
other words: program with vec_ptype_common() but play with
vec_ptype_show().)
-
The common type of atomic vectors is computed very similar to the rules of base R, except that we do not coerce to character automatically:
vec_ptype_show(logical(), integer(), double()) #> Prototype: <double> #> 0. ( , <logical> ) = <logical> #> 1. ( <logical> , <integer> ) = <integer> #> 2. ( <integer> , <double> ) = <double> vec_ptype_show(logical(), character()) #> Error in `vec_ptype_show()`: #> ! Can't combine `out_types[[i - 1]]` <logical> and `in_types[[i]]` <character>. -
Matrices and arrays are automatically broadcast to higher dimensions:
vec_ptype_show( array(1, c(0, 1)), array(1, c(0, 2)) ) #> Prototype: <double[,2]> #> 0. ( , <double[,1]> ) = <double[,1]> #> 1. ( <double[,1]> , <double[,2]> ) = <double[,2]> vec_ptype_show( array(1, c(0, 1)), array(1, c(0, 3)), array(1, c(0, 3, 4)), array(1, c(0, 3, 4, 5)) ) #> Prototype: <double[,3,4,5]> #> 0. ( , <double[,1]> ) = <double[,1]> #> 1. ( <double[,1]> , <double[,3]> ) = <double[,3]> #> 2. ( <double[,3]> , <double[,3,4]> ) = <double[,3,4]> #> 3. ( <double[,3,4]> , <double[,3,4,5]> ) = <double[,3,4,5]>Provided that the dimensions follow the vctrs recycling rules:
vec_ptype_show( array(1, c(0, 2)), array(1, c(0, 3)) ) #> Error: #> ! Can't combine `out_types[[i - 1]]` <double[,2]> and `in_types[[i]]` <double[,3]>. #> ✖ Incompatible sizes 2 and 3 along axis 2. -
Factors combine levels in the order in which they appear.
fa <- factor("a") fb <- factor("b") levels(vec_ptype_common(fa, fb)) #> [1] "a" "b" levels(vec_ptype_common(fb, fa)) #> [1] "b" "a" -
Combining a date and date-time yields a date-time:
vec_ptype_show(new_date(), new_datetime()) #> Prototype: <datetime<local>> #> 0. ( , <date> ) = <date> #> 1. ( <date> , <datetime<local>> ) = <datetime<local>>When combining two date times, the timezone is taken from the first input:
vec_ptype_show( new_datetime(tzone = "US/Central"), new_datetime(tzone = "Pacific/Auckland") ) #> Prototype: <datetime<US/Central>> #> 0. ( , <datetime<US/Central>> ) = <datetime<US/Central>> #> 1. ( <datetime<US/Central>> , <datetime<Pacific/Auckland>> ) = <datetime<US/Central>>Unless it’s the local timezone, in which case any explicit time zone will win:
vec_ptype_show( new_datetime(tzone = ""), new_datetime(tzone = ""), new_datetime(tzone = "Pacific/Auckland") ) #> Prototype: <datetime<Pacific/Auckland>> #> 0. ( , <datetime<local>> ) = <datetime<local>> #> 1. ( <datetime<local>> , <datetime<local>> ) = <datetime<local>> #> 2. ( <datetime<local>> , <datetime<Pacific/Auckland>> ) = <datetime<Pacific/Auckland>> -
The common type of two data frames is the common type of each column that occurs in both data frames:
vec_ptype_show( data.frame(x = FALSE), data.frame(x = 1L), data.frame(x = 2.5) ) #> Prototype: <data.frame<x:double>> #> 0. ( , <data.frame<x:logical>> ) = <data.frame<x:logical>> #> 1. ( <data.frame<x:logical>> , <data.frame<x:integer>> ) = <data.frame<x:integer>> #> 2. ( <data.frame<x:integer>> , <data.frame<x:double>> ) = <data.frame<x:double>>And the union of the columns that only occur in one:
vec_ptype_show(data.frame(x = 1, y = 1), data.frame(y = 1, z = 1)) #> Prototype: <data.frame< #> x: double #> y: double #> z: double #> >> #> 0. ┌ , <data.frame< ┐ = <data.frame< #> │ x: double │ x: double #> │ y: double │ y: double #> └ >> ┘ >> #> 1. ┌ <data.frame< , <data.frame< ┐ = <data.frame< #> │ x: double y: double │ x: double #> │ y: double z: double │ y: double #> │ >> >> │ z: double #> └ ┘ >>Note that new columns are added on the right-hand side. This is consistent with the way that factor levels and time zones are handled.
Casting to specified type
vec_ptype_common() finds the common type of a set of
vector. Typically, however, what you want is a set of vectors coerced to
that common type. That’s the job of vec_cast_common():
str(vec_cast_common(
FALSE,
1:5,
2.5
))
#> List of 3
#> $ : num 0
#> $ : num [1:5] 1 2 3 4 5
#> $ : num 2.5
str(vec_cast_common(
factor("x"),
factor("y")
))
#> List of 2
#> $ : Factor w/ 2 levels "x","y": 1
#> $ : Factor w/ 2 levels "x","y": 2
str(vec_cast_common(
data.frame(x = 1),
data.frame(y = 1:2)
))
#> List of 2
#> $ :'data.frame': 1 obs. of 2 variables:
#> ..$ x: num 1
#> ..$ y: int NA
#> $ :'data.frame': 2 obs. of 2 variables:
#> ..$ x: num [1:2] NA NA
#> ..$ y: int [1:2] 1 2Alternatively, you can cast to a specific prototype using
vec_cast():
# Cast succeeds
vec_cast(c(1, 2), integer())
#> [1] 1 2
# Cast fails
vec_cast(c(1.5, 2.5), factor("a"))
#> Error:
#> ! Can't convert `c(1.5, 2.5)` <double> to <factor<4d52a>>.If a cast is possible in general (i.e., double -> integer), but information is lost for a specific input (e.g. 1.5 -> 1), it will generate an error.
vec_cast(c(1.5, 2), integer())
#> Error:
#> ! Can't convert from `c(1.5, 2)` <double> to <integer> due to loss of precision.
#> • Locations: 1You can suppress the lossy cast errors with
allow_lossy_cast():
allow_lossy_cast(
vec_cast(c(1.5, 2), integer())
)
#> [1] 1 2This will suppress all lossy cast errors. Supply prototypes if you want to be specific about the type of lossy cast allowed:
allow_lossy_cast(
vec_cast(c(1.5, 2), integer()),
x_ptype = double(),
to_ptype = integer()
)
#> [1] 1 2The set of casts should not be more permissive than the set of coercions. This is not enforced but it is expected from classes to follow the rule and keep the coercion ecosystem sound.
Size
vec_size() was motivated by the need to have an
invariant that describes the number of “observations” in a data
structure. This is particularly important for data frames, as it’s
useful to have some function such that f(data.frame(x))
equals f(x). No base function has this property:
length(data.frame(x))equals1because the length of a data frame is the number of columns.nrow(data.frame(x))does not equalnrow(x)becausenrow()of a vector isNULL.NROW(data.frame(x))equalsNROW(x)for vectorx, so is almost what we want. But becauseNROW()is defined in terms oflength(), it returns a value for every object, even types that can’t go in a data frame, e.g.data.frame(mean)errors even thoughNROW(mean)is1.
We define vec_size() as follows:
- It is the length of 1d vectors.
- It is the number of rows of data frames, matrices, and arrays.
- It throws error for non vectors.
Given vec_size(), we can give a precise definition of a
data frame: a data frame is a list of vectors where every vector has the
same size. This has the desirable property of trivially supporting
matrix and data frame columns.
Slicing
vec_slice() is to vec_size() as
[ is to length(); i.e., it allows you to
select observations regardless of the dimensionality of the underlying
object. vec_slice(x, i) is equivalent to:
-
x[i]whenxis a vector. -
x[i, , drop = FALSE]whenxis a data frame. -
x[i, , , drop = FALSE]whenxis a 3d array.
x <- sample(1:10)
df <- data.frame(x = x)
vec_slice(x, 5:6)
#> [1] 4 1
vec_slice(df, 5:6)
#> x
#> 1 4
#> 2 1vec_slice(data.frame(x), i) equals
data.frame(vec_slice(x, i)) (modulo variable and row
names).
Prototypes are generated with vec_slice(x, 0L); given a
prototype, you can initialize a vector of given size (filled with
NAs) with vec_init().
Common sizes: recycling rules
Closely related to the definition of size are the recycling
rules. The recycling rules determine the size of the output
when two vectors of different sizes are combined. In vctrs, the
recycling rules are encoded in vec_size_common(), which
gives the common size of a set of vectors:
vec_size_common(1:3, 1:3, 1:3)
#> [1] 3
vec_size_common(1:10, 1)
#> [1] 10
vec_size_common(integer(), 1)
#> [1] 0vctrs obeys a stricter set of recycling rules than base R. Vectors of
size 1 are recycled to any other size. All other size combinations will
generate an error. This strictness prevents common mistakes like
dest == c("IAH", "HOU")), at the cost of occasionally
requiring an explicit calls to rep().
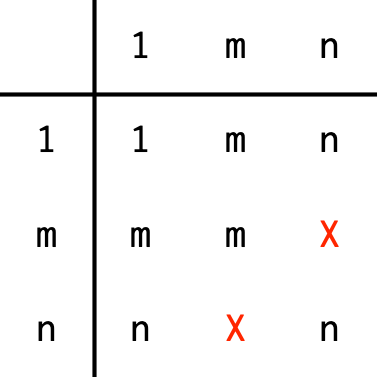
You can apply the recycling rules in two ways:
-
If you have a vector and desired size, use
vec_recycle():vec_recycle(1:3, 3) #> [1] 1 2 3 vec_recycle(1, 10) #> [1] 1 1 1 1 1 1 1 1 1 1 -
If you have multiple vectors and you want to recycle them to the same size, use
vec_recycle_common():vec_recycle_common(1:3, 1:3) #> [[1]] #> [1] 1 2 3 #> #> [[2]] #> [1] 1 2 3 vec_recycle_common(1:10, 1) #> [[1]] #> [1] 1 2 3 4 5 6 7 8 9 10 #> #> [[2]] #> [1] 1 1 1 1 1 1 1 1 1 1
Appendix: recycling in base R
The recycling rules in base R are described in The R Language Definition but are not implemented in a single function and thus are not applied consistently. Here, I give a brief overview of their most common realisation, as well as showing some of the exceptions.
Generally, in base R, when a pair of vectors is not the same length, the shorter vector is recycled to the same length as the longer:
rep(1, 6) + 1
#> [1] 2 2 2 2 2 2
rep(1, 6) + 1:2
#> [1] 2 3 2 3 2 3
rep(1, 6) + 1:3
#> [1] 2 3 4 2 3 4If the length of the longer vector is not an integer multiple of the length of the shorter, you usually get a warning:
invisible(pmax(1:2, 1:3))
#> Warning in pmax(1:2, 1:3): an argument will be fractionally recycled
invisible(1:2 + 1:3)
#> Warning in 1:2 + 1:3: longer object length is not a multiple of
#> shorter object length
invisible(cbind(1:2, 1:3))
#> Warning in cbind(1:2, 1:3): number of rows of result is not a multiple
#> of vector length (arg 1)But some functions recycle silently:
length(atan2(1:3, 1:2))
#> [1] 3
length(paste(1:3, 1:2))
#> [1] 3
length(ifelse(1:3, 1:2, 1:2))
#> [1] 3And data.frame() throws an error:
data.frame(1:2, 1:3)
#> Error in `data.frame()`:
#> ! arguments imply differing number of rows: 2, 3The R language definition states that “any arithmetic operation involving a zero-length vector has a zero-length result”. But outside of arithmetic, this rule is not consistently followed:
# length-0 output
1:2 + integer()
#> integer(0)
atan2(1:2, integer())
#> numeric(0)
pmax(1:2, integer())
#> integer(0)
# dropped
cbind(1:2, integer())
#> [,1]
#> [1,] 1
#> [2,] 2
# recycled to length of first
ifelse(rep(TRUE, 4), integer(), character())
#> [1] NA NA NA NA
# preserved-ish
paste(1:2, integer())
#> [1] "1 " "2 "
# Errors
data.frame(1:2, integer())
#> Error in `data.frame()`:
#> ! arguments imply differing number of rows: 2, 0